
بستن
0 محصول
مشاهده سبد خرید

در زیرساختهای امروزی، در دسترس بودن سرویسها یکی از مهمترین الزامات شبکه و امنیت محسوب میشود. قطع شدن یک فایروال، سرور، لینک اینترنت یا سرویس حیاتی میتواند باعث توقف فعالیت کاربران، اختلال در سرویسهای سازمانی و ایجاد هزینههای قابلتوجه شود. به همین دلیل سازمانها از روشهایی استفاده میکنند که احتمال قطعی سرویس را به حداقل برساند. یکی از مهمترین این روشها High Availability (HA) است. اما چرا High Availability در طراحی شبکههای مدرن اهمیت بالایی دارد؟
در این مقاله مفهوم HA ، نحوه عملکرد، انواع معماریها، مکانیزم Failover و کاربردهای آن را بهصورت تخصصی بررسی میکنیم.
High Availability یا HA مجموعهای از معماریها، فناوریها و مکانیزمهایی است که برای افزایش دسترسپذیری سرویسها و کاهش زمان قطعی (Downtime) طراحی شدهاند.
هدف اصلی HA این است که در صورت خرابی یک جزء از زیرساخت، سرویس بدون ایجاد اختلال قابلتوجه به فعالیت خود ادامه دهد. به عبارت دیگر، اگر یکی از تجهیزات یا سرویسهای حیاتی دچار مشکل شود، یک سیستم جایگزین بهصورت خودکار مسئولیت ادامه سرویس را بر عهده میگیرد.
بهعنوان مثال:
فرض کنید در یک سازمان فقط یک فایروال وجود دارد. اگر این فایروال دچار خرابی سختافزاری شود:
اما در صورتی که ساختار High Availability (HA) پیادهسازی شده باشد:
این فرآیند معمولاً در مدت زمان بسیار کوتاهی انجام میشود.
در شبکههای سازمانی، Availability (دسترسپذیری) یکی از مهمترین شاخصهای طراحی زیرساخت محسوب میشود. حتی چند دقیقه قطعی در سرویسهای مهم مانند فایروال، VPN، سرورها یا سیستمهای مالی میتواند منجر به اختلال در فرآیندهای عملیاتی و ایجاد هزینه مستقیم و غیرمستقیم برای سازمان شود.
هرچه وابستگی کسبوکار به سرویسهای دیجیتال بیشتر باشد، نیاز به پیادهسازی High Availability (HA) بهعنوان یک لایه محافظتی در برابر خرابی تجهیزات و سرویسها، اهمیت بیشتری پیدا میکند.
در واقع، HA با هدف حذف Single Point of Failure (SPOF) و کاهش Downtime طراحی میشود و تضمین میکند که سرویسها در صورت بروز خطا، بدون وقفه قابل توجه به کار خود ادامه دهند.
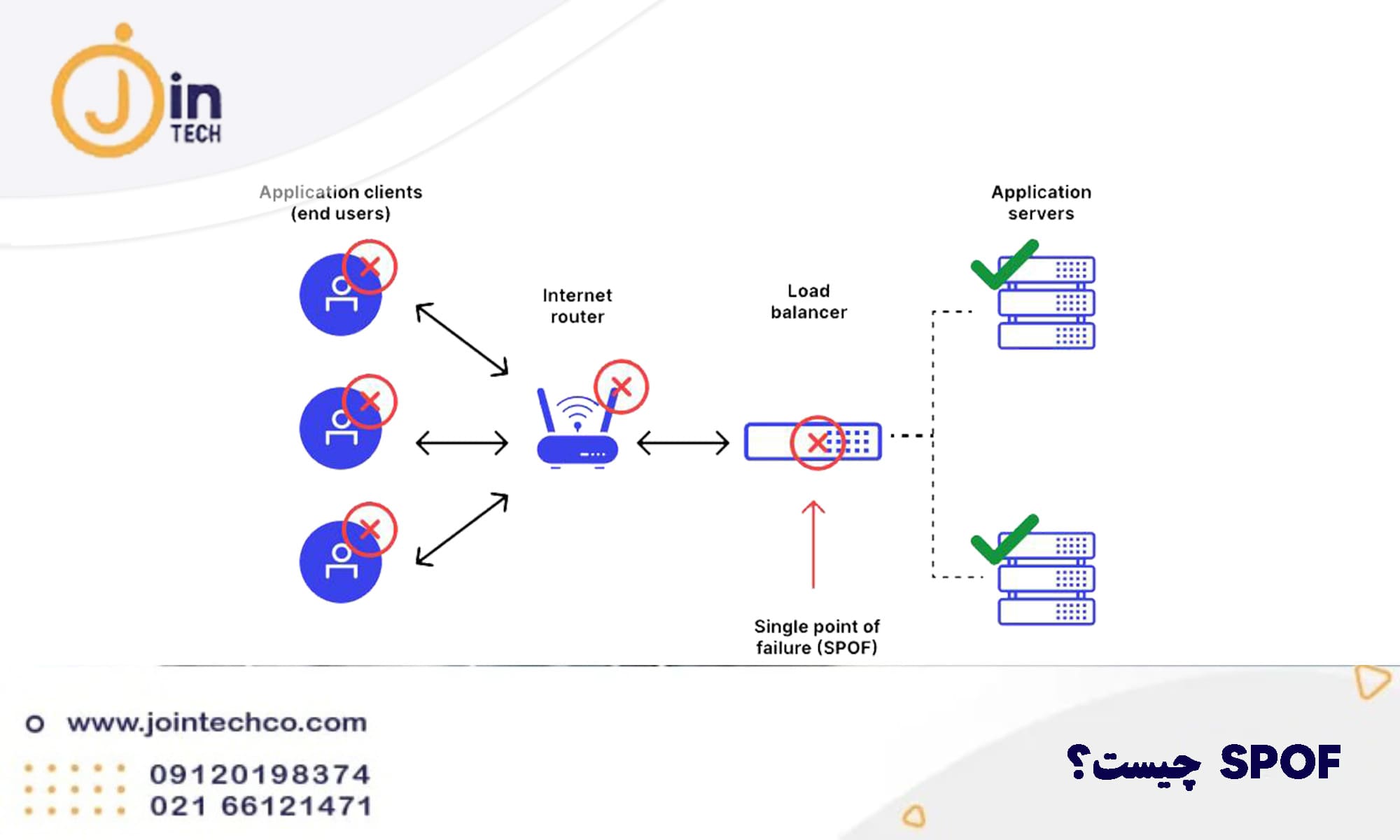
SPOF به نقطهای در شبکه گفته میشود که در صورت خرابی آن، کل سرویس یا بخش مهمی از سیستم از کار میافتد.
مثال:
هدف اصلی High Availability حذف همین نقاط حساس است.
مهمترین هدف High Availability، به حداقل رساندن زمان از دسترس خارج شدن سرویسها است. در معماریهای استاندارد، Failover باید بهگونهای طراحی شود که انتقال سرویس در کمترین زمان ممکن و با حداقل اختلال برای کاربران انجام شود.
با استفاده از ساختارهای افزونه (Redundant)، خرابی یک تجهیز یا سرویس، کل شبکه را تحت تأثیر قرار نمیدهد. در نتیجه، این موضوع باعث میشود شبکه در برابر خطاهای سختافزاری، نرمافزاری یا حتی اختلالات لینک مقاومتر باشد.
در یک زیرساخت مجهز به HA، سرویسها رفتار قابل پیشبینیتری دارند و احتمال از کار افتادن کامل یک سرویس بهشدت کاهش پیدا میکند. این موضوع برای سرویسهای حیاتی مانند Authentication، VPN و Firewall بسیار مهم است.
یکی از اهداف مهم HA این است که کاربران نهایی حتیالامکان متوجه وقوع Failover نشوند. در صورت طراحی صحیح (بهخصوص با Session Synchronization)، ارتباطات فعال مانند VPN، دانلودها یا نشستهای وب بدون قطع شدن ادامه پیدا میکنند.
سازمانهایی که سرویسهای حیاتی مانند ایمیل، ERP، بانکهای اطلاعاتی یا سیستمهای مالی دارند، HA نقش مستقیم در استمرار فعالیت کسبوکار دارد. در واقع HA بخشی از استراتژی کلی Business Continuity و Disaster Recovery محسوب میشود.
در معماری High Availability معمولاً چند مؤلفه اصلی وجود دارد:
مرحله اول:
دستگاه اصلی سرویسها را پردازش میکند.
مرحله دوم:
سیستم پشتیبان دائماً وضعیت دستگاه اصلی را بررسی میکند.
مرحله سوم:
در صورت تشخیص خرابی:
سیستم جایگزین فعال میشود.
مرحله چهارم: ترافیک شبکه به سمت دستگاه جایگزین هدایت میشود.
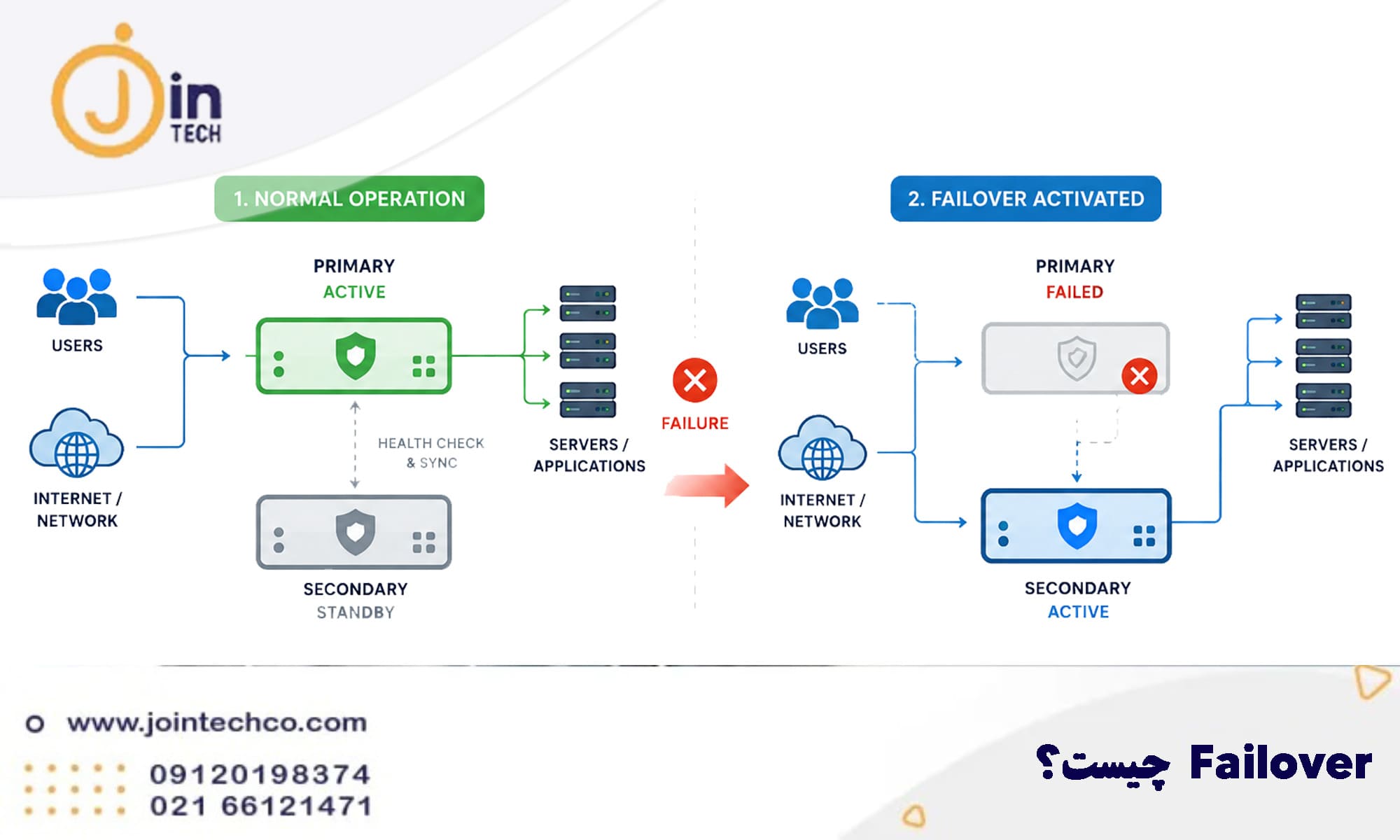
یکی از مهمترین اجزای معماری High Availability (HA) مکانیزم Failover است.
Failover فرآیندی است که در صورت خرابی، اختلال یا در دسترس نبودن سیستم اصلی، سرویسها بهصورت خودکار یا کنترلشده به سیستم جایگزین منتقل میشوند تا قطعی سرویس به حداقل برسد یا کاملاً مخفی بماند.
این مکانیزم به سیستم اجازه میدهد که در برابر خطاهای سختافزاری، نرمافزاری یا ارتباطی مقاوم باشد و سرویس بدون توقف ادامه پیدا کند.
در یک ساختار HA، فرآیند Failover معمولاً شامل مراحل زیر است:
سیستم پشتیبان بهصورت مداوم وضعیت دستگاه Active را بررسی میکند.
در صورت قطع ارتباط، Crash شدن سرویس یا عدم پاسخ به Health Check، وضعیت خرابی تشخیص داده میشود.
دستگاه پشتیبان وارد حالت Active میشود و نقش اصلی را بر عهده میگیرد.
ترافیک شبکه و سرویسهای در حال اجرا به سمت دستگاه جدید هدایت میشوند.
در صورت وجود Session Synchronization، ارتباط کاربران بدون قطع محسوس ادامه پیدا میکند.
زمان انجام Failover در همه سیستمها یکسان نیست و به عوامل زیر بستگی دارد:
در سیستمهای حرفهای (مثل فایروالهای Enterprise)، Failover میتواند در حد چند ثانیه یا حتی کمتر انجام شود.
نکته:
Failover همیشه به معنی «صفر شدن قطعی» نیست. در برخی سناریوها ممکن است:
Redundancy به معنی ایجاد منابع یا تجهیزات اضافی برای جلوگیری از نقطه شکست (Single Point of Failure) است.
مثال:
اما موجود داشتن تجهیزات اضافه به معنی HA نیست.
High Availability علاوه بر وجود تجهیزات اضافی، شامل مکانیزم مدیریت خرابی و انتقال سرویس نیز میشود.
معماریهای High Availability (HA) معمولاً به دو مدل اصلی تقسیم میشوند که هرکدام بر اساس نوع استفاده از منابع و نحوه مدیریت ترافیک طراحی شدهاند.
در معماری Active-Passive:
این مدل سادهترین نوع پیادهسازی HA محسوب میشود و تمرکز اصلی آن بر پایداری و اطمینان از Failover سریع است، نه استفاده حداکثری از منابع.
مزایا:
معایب:
موارد استفاده:
در معماری Active-Active:
در این مدل، تمرکز اصلی بر افزایش کارایی و استفاده حداکثری از منابع سختافزاری است.
مزایا:
معایب:
موارد استفاده:
در شبکههای مدرن، بسیاری از ارتباطات کاربران stateful هستند؛ یعنی فقط یک اتصال ساده نیستند، بلکه دارای وضعیت (Session State) میباشند. این وضعیت شامل اطلاعاتی مانند IP مبدا و مقصد، پورتها، وضعیت TCP handshake، جدول NAT و اطلاعات احراز هویت کاربر است.
Session Synchronization در High Availability به فرآیندی گفته میشود که در آن این اطلاعات (بین تجهیزات Active و Standby) یا (بین نودهای Active-Active) بهصورت مداوم همگامسازی میشود.
در صورتی که Sessionها بین دو دستگاه همگامسازی نشوند، هنگام Failover سیستم جدید هیچ اطلاعی از ارتباطات قبلی کاربران نخواهد داشت. در نتیجه:
به همین دلیل در طراحی HA، صرفاً فعال بودن دستگاه دوم کافی نیست؛ بلکه باید وضعیت دقیق ارتباطات نیز منتقل شود.
در یک ساختار High Availability:
این فرآیند معمولاً از طریق لینک اختصاصی HA یا شبکه داخلی امن بین دو دستگاه انجام میشود.
بسته به نوع تجهیزات (مثل فایروالها)، موارد زیر معمولاً همگامسازی میشوند:
با وجود Session Synchronization، همیشه همه چیز 100٪ بدون قطعی نیست. برخی موارد ممکن است همچنان باعث قطع لحظهای شوند:
High Availability تنها به فایروال محدود نمیشود و در بخشهای مختلف شبکه استفاده میشود:
خیر. High Availability فقط احتمال قطعی و زمان آن را کاهش میدهد.
عوامل خرابی همچنان میتوانند وجود داشته باشند:


